Text, image, video, audio, multimodal
AI training data services
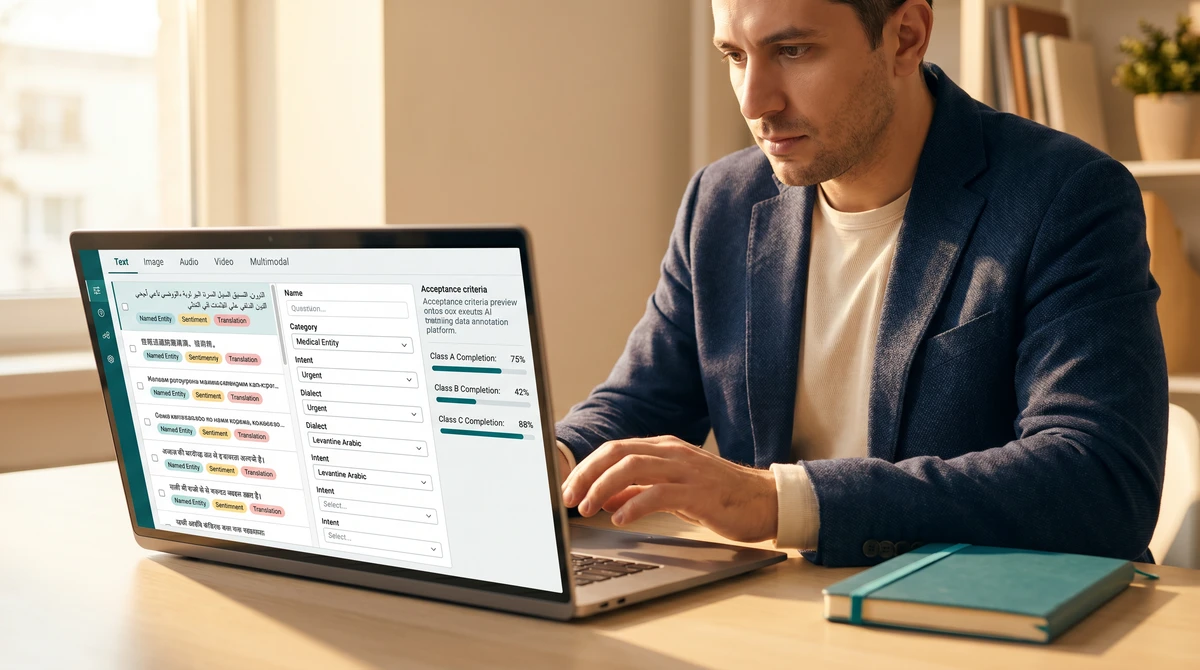
Source AI training data with modality, language, and acceptance defined first.
Receive a training-ready dataset with the modality mix, language coverage, label categories, reviewer instructions, and acceptance criteria settled in writing before any data work begins.
Upload files for a quote
Short form: name, work email, data type, locale notes, and sample files or links if ready.
Native-script reviewers per language pair
Standard for a 10,000-row multilingual text dataset
Confidentiality controls before any data transfer
Dynamic Dialects supports requests across 250+ languages with ISO 9001/27001 operating controls, ISO 17100 applied to translation scopes, 40,000+ vetted linguists, named project coordination, and written confirmation before production work begins.
Evidence for review
What DD can show before a buyer commits.
This is not a public case study claim. It is DD-owned evidence a buyer can request when the work needs vendor review before a scope is approved.
Ask for proof details- Buyer type
- AI training data services buyer, vendor manager, or operations lead qualifying DD before sending a live requirement.
- Problem
- The buyer needs source ai training data with modality, language, and acceptance defined first. scoped by files, audience, language pair, deadline, recipient rules, and review process before quote approval.
- Scope
- AI training data services work coordinated by DD with written request review, named PM ownership, and review records matched to the request type.
- Constraint
- This page cannot rely on a public case study yet; it must point to DD-owned proof artifacts and disclosure-safe process evidence.
- DD action
- DD confirms the inputs, missing details, staffing option, quality check, and delivery record before production work begins.
- Evidence available
- Private proof can include a request-specific checklist, redacted QA summary format, delivery record format, and sourcing or reviewer notes.
- Outcome
- The buyer can judge whether DD fits the requirement before sending production files or adding this service to a vendor shortlist.
- Disclosure status
- DD-owned proof only. Public outcomes require client approval; redacted process artifacts can be shared when terms allow.
How the work runs
-
Scope the dataset
Modality, target size, label categories with examples per class, acceptance criteria, and output format recorded in writing before any data work begins.
-
Calibrate on samples
A small sample run through the rules first, with results checked against your expectation. Rule-set ambiguity gets caught in 50 rows rather than 5,000.
-
Build the dataset
Native-script reviewers per language pair work in tracked batches with reviewer instructions visible and progress recorded per class.
-
Run reviewer pass and acceptance check
A second qualified reviewer checks the dataset against the acceptance criteria set at step 1; a per-class summary is built for the final report.
-
Deliver in your ingestion format
Training-ready dataset in the requested output format (JSONL, TFRecord, Parquet, COCO, YOLO, or platform-specific export) ready to drop into your model pipeline.
Each AI training data project starts with a written request check confirming dataset modality (text, image, video, audio, multimodal), language coverage, label categories with examples per class, reviewer instructions, acceptance criteria, output format, and confidentiality controls. Sample data is run through the rules and reviewed against your expectation before bulk work begins. Multilingual training data is built with native-script reviewers per language pair rather than a single English-first reviewer applied across all locales. Standard turnaround for a 10,000-row multilingual text dataset is 10–14 working days; multimodal and rare-language work is quoted with a confirmed delivery date in writing.
For annotation work, DD checks label definitions, examples, sample review needs, and output format before quoting.
What this page helps you send
- LLM fine-tuning data: instruction–response pairs, preference rankings, and rejection-sampling sets in target languages.
- Multilingual evaluation sets: factuality, toxicity, refusal, and persona-fidelity benchmarks in 250+ languages.
- Speech datasets: transcribed and labeled audio for speech recognition, speaker diarization, and prosody work.
- Computer vision datasets: labeled image and video sets for object detection, segmentation, and classification.
- Multimodal datasets: image–text, video–caption, and screenshot–intent pairs with consistency across modalities.
- Conversational AI datasets: dialog turns with annotations for intent, sentiment, and dialog act per turn.
- Rare-language training data where most marketplaces cannot source qualified reviewers.
- Continuous data programs running on a defined cadence rather than one-off batches.
What you receive
- Training-ready dataset in the requested output format, ready for ingestion into your model pipeline.
- Sample-row calibration report showing rule application before bulk work began.
- Per-row reviewer trace so any flagged label is attributable to a named source.
- Reviewer notes for edge cases, ambiguous rows, and label-rule clarifications added during the work.
- Acceptance summary tied to the criteria recorded at the start, with a per-class breakdown.
Questions teams ask first
What is the difference between AI training data and data labeling?
Data labeling is the process of applying labels to existing data. AI training data is the output a model team actually uses (a curated, labeled, reviewed dataset ready for ingestion). Training data work includes collection, labeling, reviewer pass, acceptance check, and format conversion in one project, so the model team receives a ready-to-train dataset rather than raw labels they still need to process.
Which dataset modalities are handled?
Text (instruction–response pairs, classification labels, span extraction, conversational data), image (bounding boxes, polygons, semantic segmentation, landmark points), video (frame-level annotation, object tracking, event detection), audio (speaker diarization, sound event tagging, transcription with prosody marks), and multimodal pairings (image–text, video–caption, screenshot–intent).
How is multilingual coverage built?
Native-script reviewers are sourced per language pair rather than a single English-first reviewer applied across all locales. For dialect-sensitive work (Levantine vs Gulf Arabic, Brazilian vs European Portuguese, Mandarin vs Cantonese), the dialect target is confirmed in the request check and reviewers are matched to it. Coverage spans 250+ languages including rare and refugee-resettlement languages most data marketplaces cannot source.
How are acceptance criteria recorded?
Acceptance criteria are written in plain text in the request check before any data work begins, with worked examples of what counts as a correct label and what counts as a flag. At delivery, an acceptance summary is provided tied back to the original criteria so the model team can verify the dataset matches the agreed scope without re-reading every row.
How is confidentiality handled for proprietary datasets?
An NDA is signed before any data transfer when requested. Data is kept on access-restricted storage, named-reviewer staffing is available for sensitive datasets, and source data is deleted on a defined schedule after project close. Reviewer access can be scoped to your security posture on request.
What output formats are supported?
JSONL, CSV, TFRecord, Parquet, COCO, YOLO, Pascal VOC, and platform-specific exports (Label Studio, Labelbox, Scale AI, SuperAnnotate, V7, Hugging Face Datasets, and others on request). Output format is confirmed during the request check so the dataset drops into your model pipeline without a separate conversion step.
Can a continuous data program be set up?
Yes. Continuous programs run on a defined cadence (daily, weekly, per-model-update) with the same reviewer pool, the same rule set, and a steady acceptance summary attached to each batch. New languages, new label categories, or rule-set changes are handled in writing rather than improvised mid-stream.
What about LLM evaluation and red-teaming data?
Evaluation sets (factuality, toxicity, refusal, persona-fidelity), preference-ranking data for RLHF, and red-team prompt sets in target languages are scoped per program. Multilingual evaluation in particular requires native-script reviewers per language and a shared evaluation rubric translated and adapted per locale.